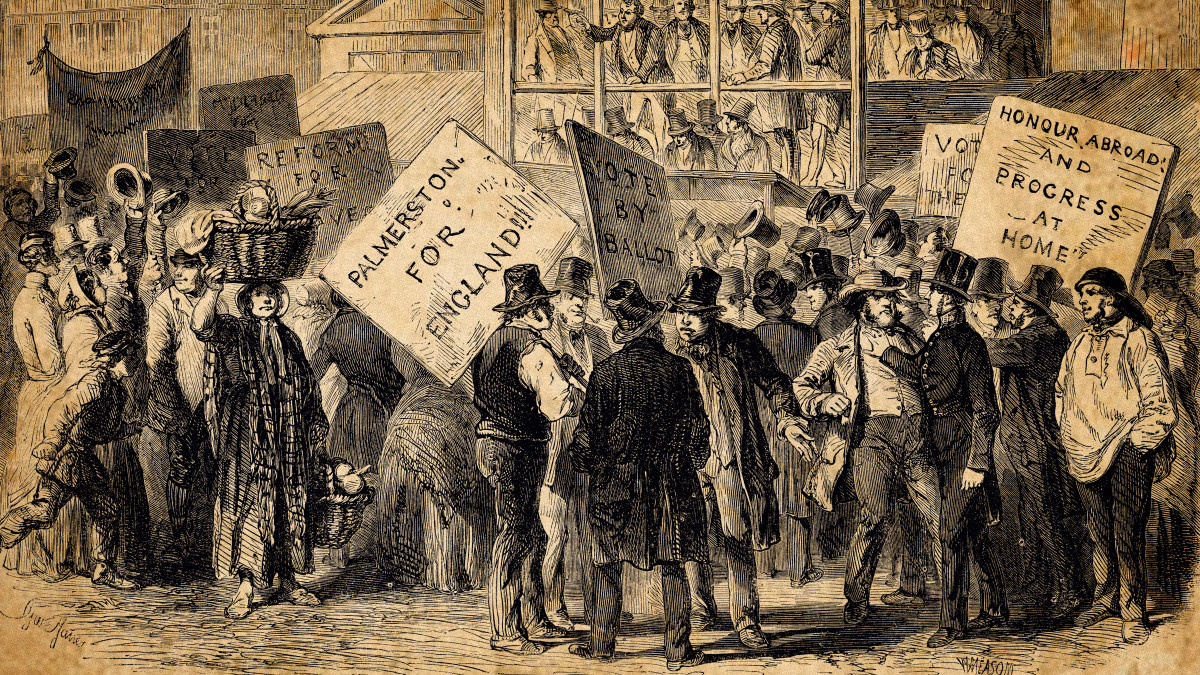
대학생이 만든 AI의 시간여행, 실수로 1834년 실제 역사를 복원하다
최근 아주 흥미로운 AI 실험에 대한 소식이 있었는데요.
'재미 삼아' 빅토리아 시대 영어를 구사하는 AI 언어 모델을 만들던 한 취미 개발자가 자신의 창작물로부터 예상치 못한 역사 강의를 듣게 된 사건입니다.
이 놀라운 발견의 주인공은 바로 펜실베이니아주 뮬렌버그 대학에서 컴퓨터 과학을 전공하는 하이크 그리고리안(Hayk Grigorian)이거든요.
그는 레딧(Reddit)을 통해 "1834년 런던에서 시위가 실제로 일어났는지 궁금해서 찾아봤는데, 정말 있었던 사건이더라고요"라며 AI가 알려준 사실을 직접 확인하고 놀라움을 표현한 것입니다.
그리고리안은 지난 한 달간 '타임캡슐LLM(TimeCapsuleLLM)'이라는 소형 AI 언어 모델을 개발해 왔는데요.
이 프로젝트는 챗GPT(ChatGPT)의 아주 먼 친척뻘 되는 모델로, 1800년부터 1875년 사이 런던에서 나온 텍스트만을 학습시켜 AI 모델에서 진정한 '빅토리아 시대의 목소리'를 담아내는 것을 목표로 한 것입니다.
그 결과, 이 AI 모델은 성경 구절 인용이 잦고 당시 시대상에 맞는 수사적 표현이 가득한 텍스트를 생성하게 되었습니다.
사실 그리고리안의 프로젝트는 '역사적 대규모 언어 모델(Historical Large Language Models, HLLMs)'이라고 불리는 성장하는 연구 분야의 일환이기도 한데요.
비슷한 프로젝트로는 1400년에서 1700년 사이의 11,000개 텍스트를 학습해 17세기 지식 체계로 주제를 토론할 수 있는 모나드GPT(MonadGPT)나, 고대 형식 규칙에 따라 중국 고전 시를 생성하는 쉰자ALLM(XunziALLM) 등이 좋은 예시입니다.
이러한 모델들은 연구자들에게 과거 시대의 언어 패턴과 상호작용할 기회를 제공하는 것이죠.
그리고리안에 따르면, 타임캡슐LLM의 가장 흥미로운 결과물은 아주 간단한 테스트에서 나왔거든요.
그가 AI에게 '때는 우리 주님의 해 1834년이었다'라는 문장으로 프롬프트를 입력하자, 사용자가 멈춘 지점부터 텍스트를 이어 생성하도록 훈련된 AI 모델이 다음과 같은 내용을 출력한 것입니다.
때는 우리 주님의 해 1834년이었고 런던의 거리는 시위와 청원으로 가득했다.
많은 이들이 이야기했듯, 그 대의는 사적인 방식으로 묶인 것이 아니라, 파머스톤 경의 날과 같은 날에 시작되었으므로, 대중은 법의 날이 우리에게 닥친 어려움에 대한 짧은 성명을 받게 될 것이다.
세계사의 현재 사건들이 명백하며, 따라서 알려지게 될 것이라는 점은 깊은 유감의 문제이다.
예루살렘의 복음서에 처음 정착한 바로 그 사람들이 번영과 번영에 대한 그토록 광범위하고 흥미로운 기록을 가졌다는 것은 사실이 아니다.
출력된 내용의 정확성이 궁금했던 그리고리안은 곧바로 사실 확인에 나섰는데요.
그는 "AI가 생성한 텍스트에 파머스톤 경(Lord Palmerston)이 언급되었는데, 구글 검색을 해보니 그의 행동이 1834년 시위의 원인이었다는 사실을 알게 되었다"고 말했습니다.
실제로 AI가 생성한 텍스트의 세부 내용은 역사적 사실과 정확히 일치하는 부분이 많았거든요.
1834년은 '빈민법 개정안(Poor Law Amendment Act 1834)'으로 인해 영국에서 상당한 시민 불안이 있었던 시기였고, 파머스톤 경은 이 격동의 시기에 영국의 외무장관을 거쳐 훗날 총리가 된 인물입니다.
어떤 면에서 보면 이 결과는 그리 놀라운 일이 아닐 수도 있는데요.
챗GPT와 같은 AI 언어 모델을 만드는 연구자들은 이미 이런 모델들이 학습한 텍스트에서 정보를 합성하여 현실적인 결과물을 만들어낼 수 있다는 것을 알고 있기 때문입니다.
오늘날 모든 AI 비서가 바로 이런 방식으로 작동하는 것이죠.
하지만 이번 사례가 특별히 흥미로운 점은, 한 개인이 만든 소규모 취미용 모델이 수천 개의 문서에 흩어져 있는 참조 자료들로부터 '일관된 역사적 순간'을 재구성해 개발자 자신을 놀라게 했다는 사실이거든요.
그리고리안은 1834년 시위 관련 문서를 의도적으로 학습시킨 적이 없었고, AI는 6.25GB에 달하는 방대한 빅토리아 시대 문헌 속에서 발견되는 주변 패턴들로부터 이러한 연결고리를 스스로 조립해낸 것입니다.
통계로 구현한 언어적 시간여행
개발자 하이크 그리고리안은 현대 텍스트 소스로 AI 언어 모델을 미세 조정하는 대신, 자신만의 독특한 방식을 사용했는데요.
그는 1800년에서 1875년 사이에 런던에서 출판된 7,000권 이상의 책, 법률 문서, 신문 등 오직 빅토리아 시대 자료만을 사용해 처음부터 AI 모델을 훈련시키는 '선택적 시간 훈련(Selective Temporal Training, STT)'이라는 과정을 거친 것입니다.
심지어 단어를 단순화된 표현으로 잘라 처리하는 맞춤형 토크나이저를 통해 현대 어휘를 완전히 배제했다고 합니다.
그리고리안은 "만약 GPT-2 같은 모델을 미세 조정한다면, 이미 사전 훈련된 정보가 사라지지 않을 것"이라며 현대 데이터 오염에 대해 설명했거든요.
"처음부터 훈련하면 언어 모델은 옛날인 척하는 것이 아니라, 그냥 옛날 그 자체가 될 것"이라는 게 그의 설명입니다.

지금까지 훈련된 세 가지 버전의 AI 모델은 각각 향상된 역사적 일관성을 보여주었는데요.
187MB 데이터로 훈련된 버전 0은 빅토리아 시대 풍의 횡설수설을 내뱉었고, 버전 0.5는 문법적으로는 정확했지만 사실을 지어내는 '환각' 증세를 보였습니다.
하지만 대여한 A100 GPU로 훈련된 현재 7억 개 매개변수 버전은 위에서 본 것과 같은 실제 역사적 사실을 생성하기 시작한 것입니다.
이러한 실험은 역사학자나 디지털 인문학 연구자들에게 매우 유용할 수 있거든요.
특정 시대의 텍스트로 AI 언어 모델을 훈련시키면, 과거에 사라진 방언이나 언어를 구사하는 시뮬레이션 화자와 대화할 기회를 연구자에게 제공하는 '상호작용형 시대 언어 모델'을 만들 수 있기 때문입니다.
그리고리안은 앞으로 "중국, 러시아, 인도 등 다른 도시 모델도 시도해보고 싶다"며 미래의 AI 모델에 대한 다른 사람들과의 협업 가능성을 열어두었는데요.
그는 자신의 작업 코드, AI 모델 가중치, 관련 문서를 모두 깃허브(GitHub)에 공개하고 있습니다.
AI의 '환각 현상', 즉 없는 사실을 지어내는 것이 자주 문제되는 요즘 시대에, 우연히 과거의 진실을 이야기하는 모델의 등장은 정말 신선하게 다가오거든요.
이는 환각의 정반대 현상, 즉 AI가 우연히 무언가를 정확히 맞추는 '사실 사고(factcident)'라고 부를 수 있을 것입니다.